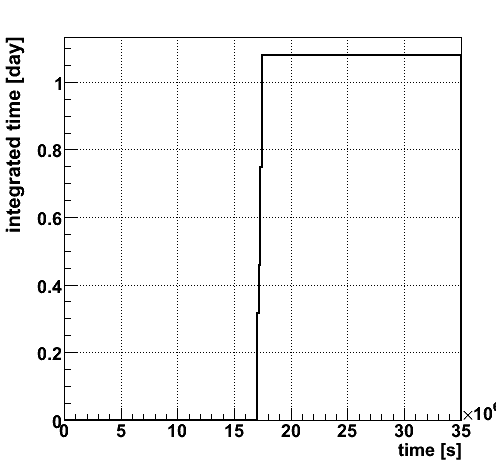
The effective livetime is 1.078 days.
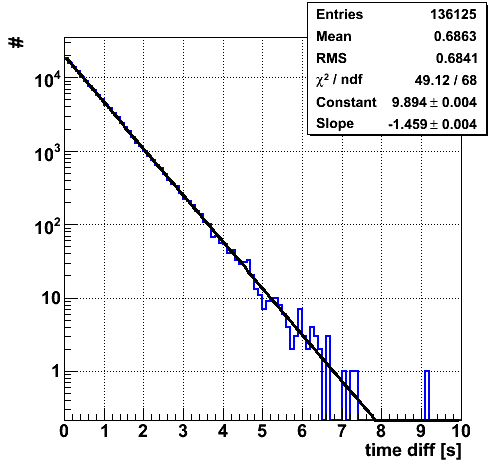
Time difference between events. Looks normal.
The rate is 1.46 Hz.
Here, I have shown several plots for the data and MC comparison for IC79 data. This comparison will be essential for the separation of EHE neutrino signals from backgrounds. Parameters are looked for that have reasonable agreement between data and background MC, but does different behavior between data and signal MC.
I have used EHE filter data whose condition is (portia) NPE is greater than one thousand.
The run number of 116180, 116200, 116210, 116220 were used for the observation data. All of the data is the part of the burn sample.
The JULIeT data (100k each) are used for signals and HE CORSIKA data with iron primary (~20k) are used for the backgrounds. The SPICE 1 tables are used for the generation.
|
The effective livetime is 1.078 days.
|
Time difference between events. Looks normal.
The rate is 1.46 Hz.
|
In following plots, the colors mean
|
NPE agreements between data and background MC is nice. 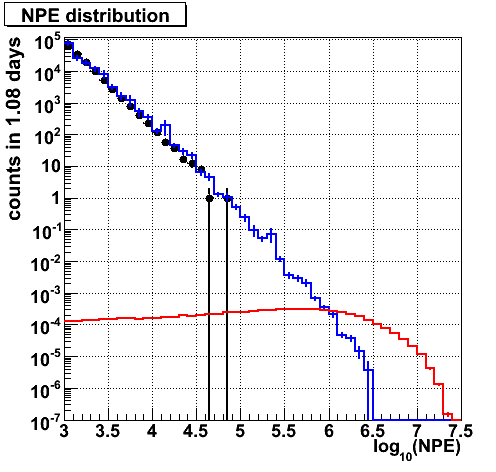
|
We see a difference in data and background MC 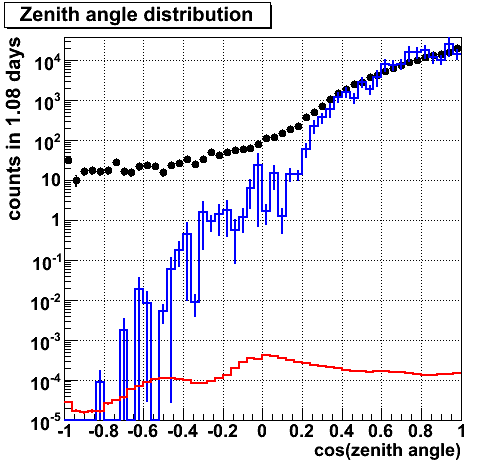
|
Distribution becomes clean when a condtion is put. 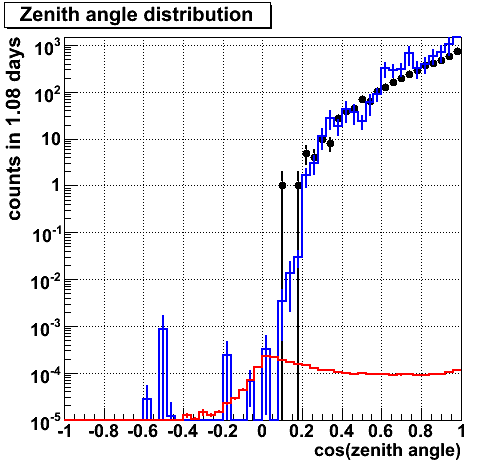
|
NDOM. 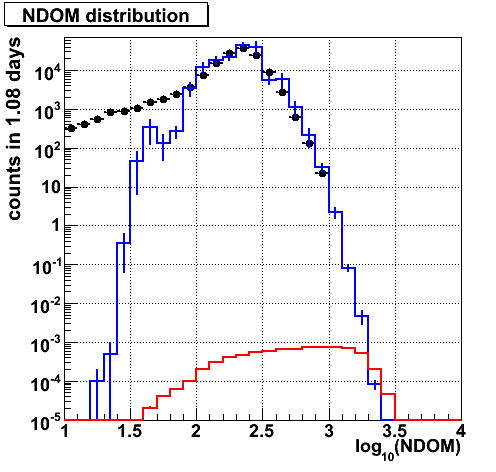
|
|
CoGX 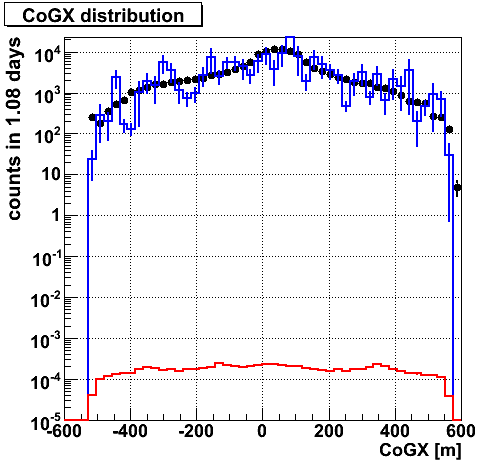
|
CoGY 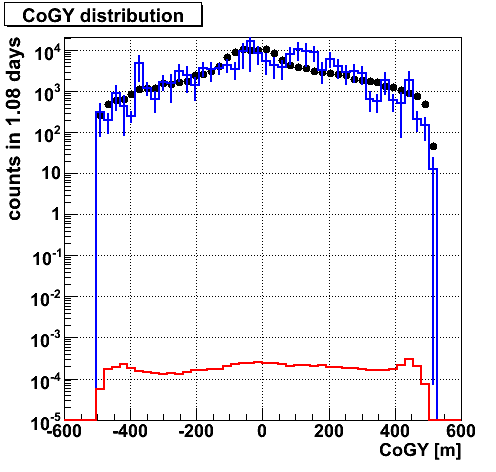
|
CoGZ. A difference seen at deeper place. 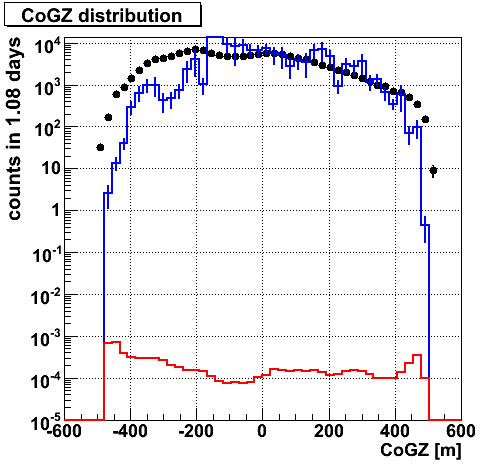
|
|
|
Closest distance. Agreement is nice. 
|
Closest distance for each contributions. 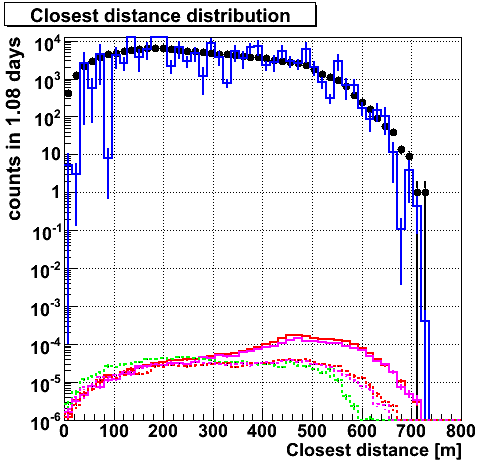
|
|
Energy (photorec). There is a tail for data. 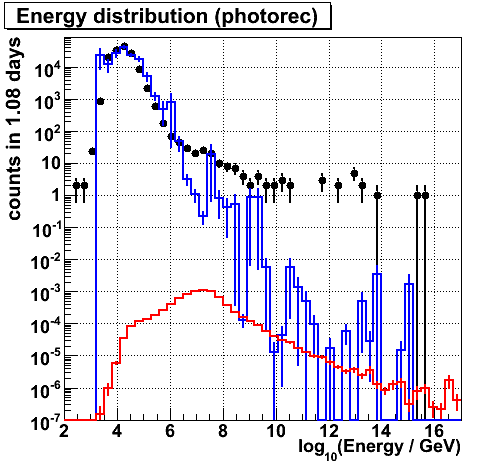
|
Energy (mue) 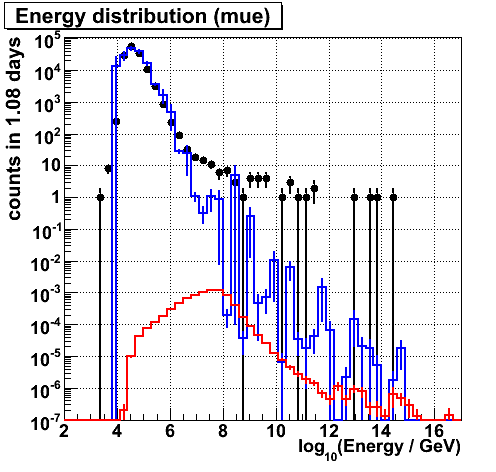
|
dE/dX 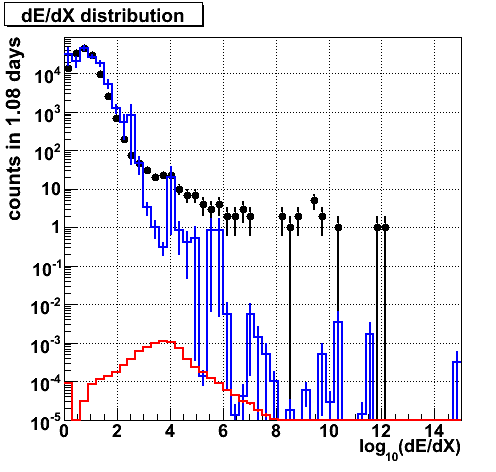
|
|
|
Energy (photorec). The tail reduced a bit. 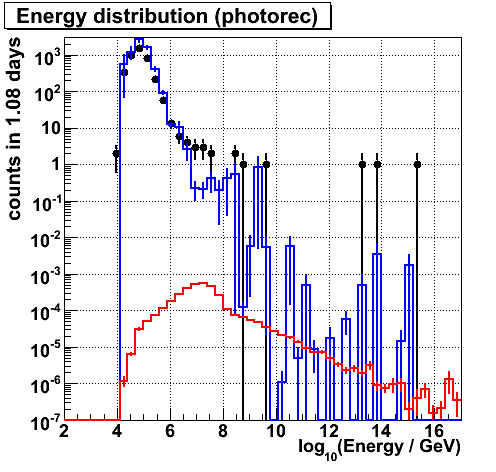
|
Energy (mue) 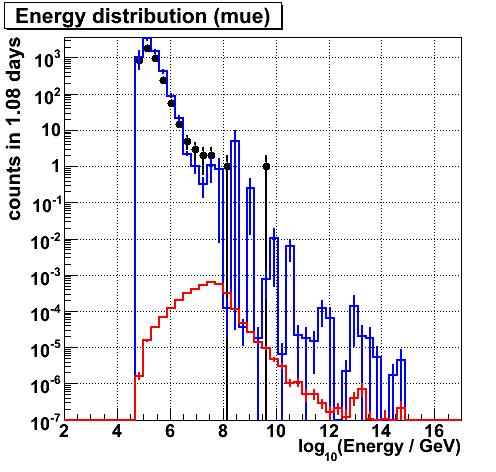
|
dE/dX 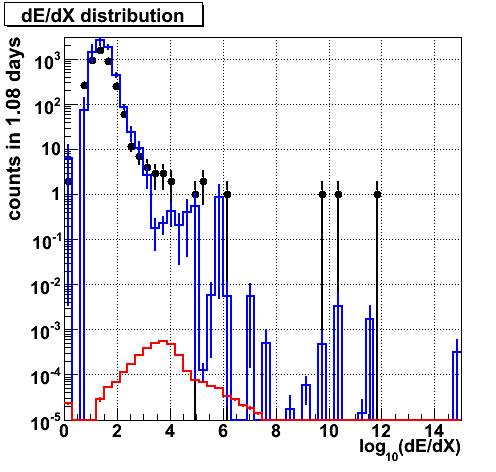
|
|
|
ZA (Linefit) 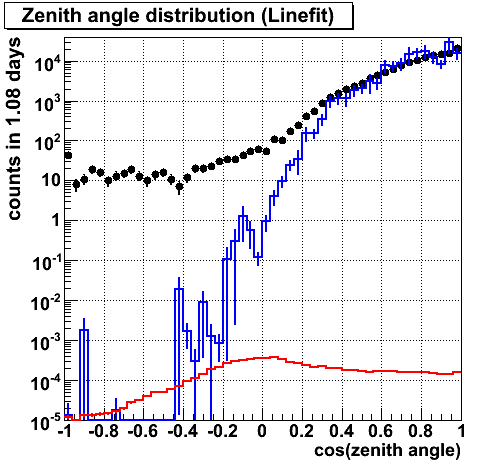
|
ZA (spe single) 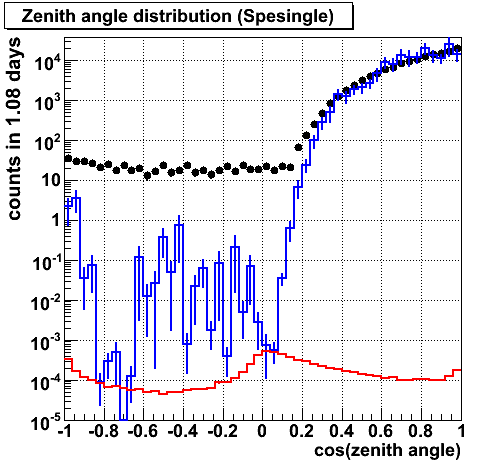
|
ZA (spe 4 iteration) 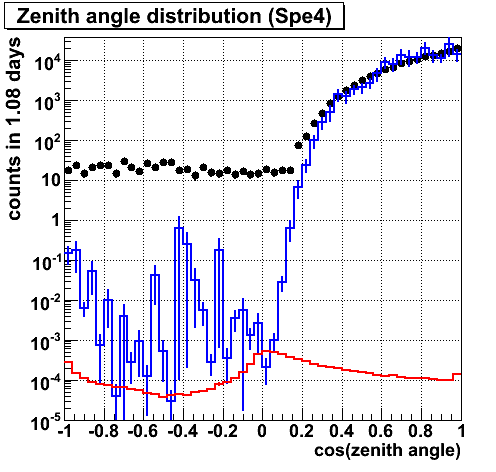
|
ZA (mpe) 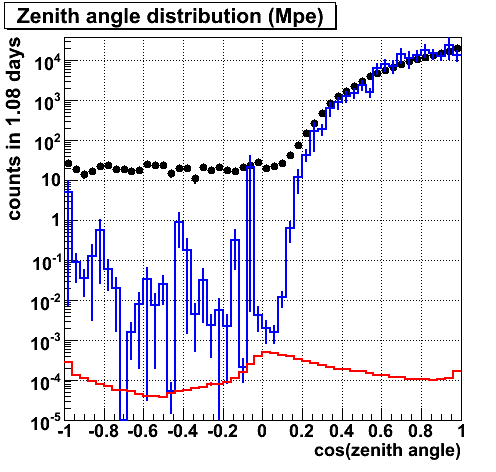
|
|
Linefit speed Z 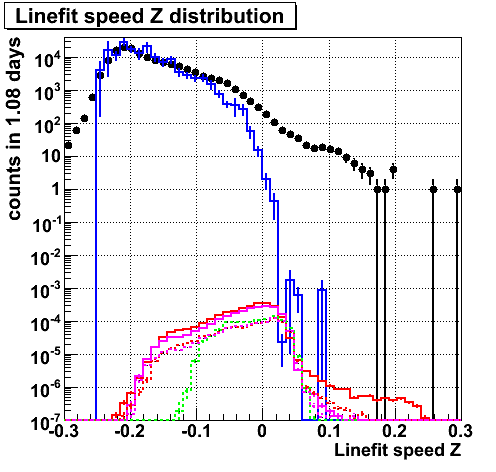
|
|
Ldir. This parameter also may be useful. 
|
Ldir 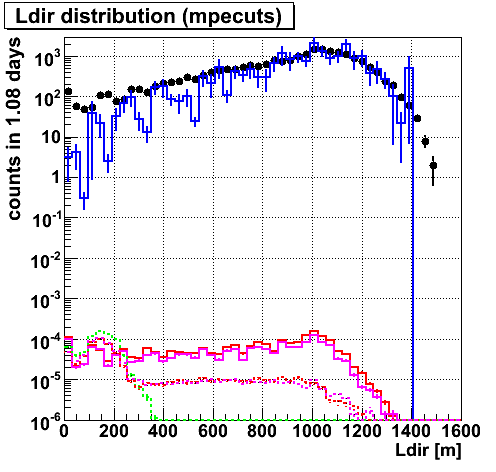
|
Ndir. 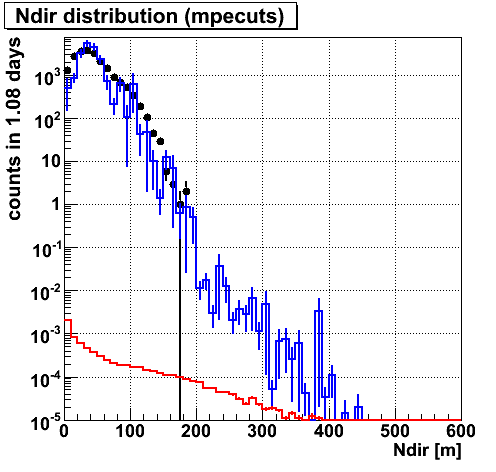
|
Ndir 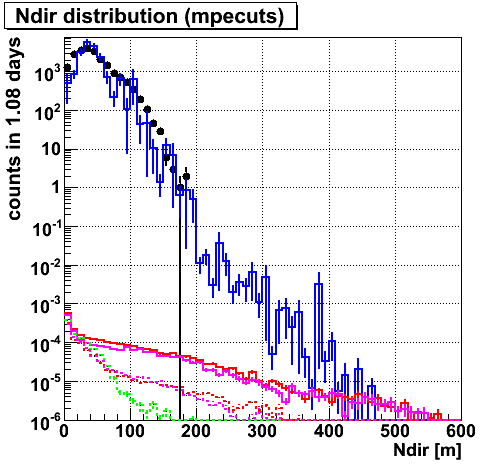
|
|
Log likelihood 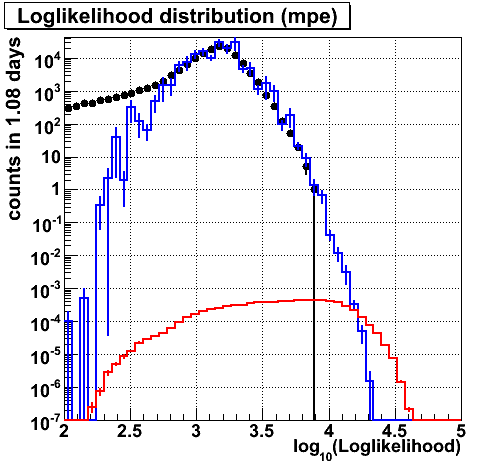
|
Log likelihood 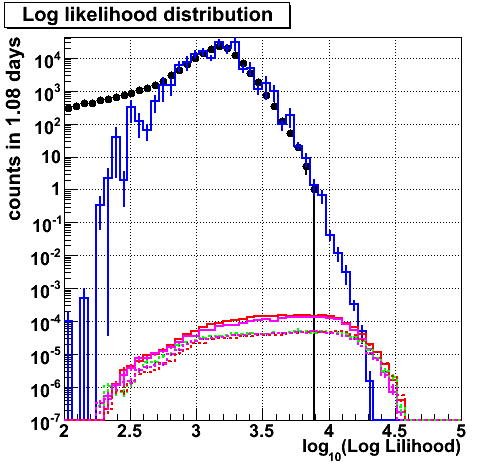
|
NDOF 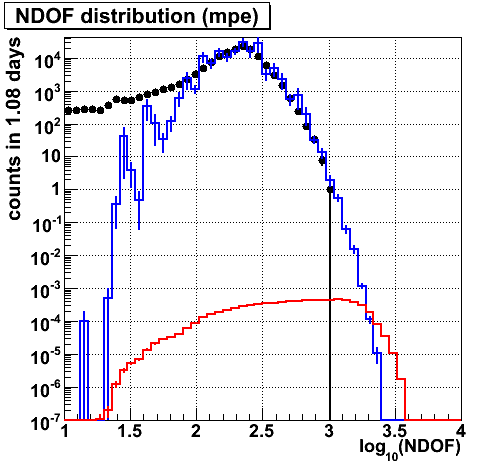
|
NDOF 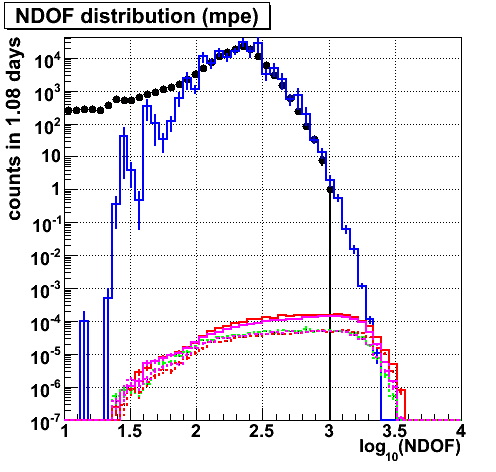
|
Look at this page for ehe-star.
|
Area ratio 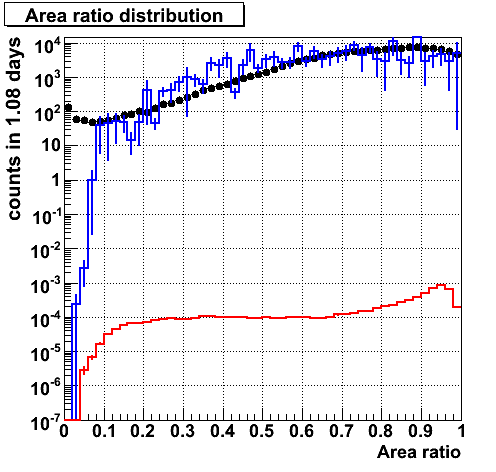
|
Area ratio from each components. nue give high area ratio. 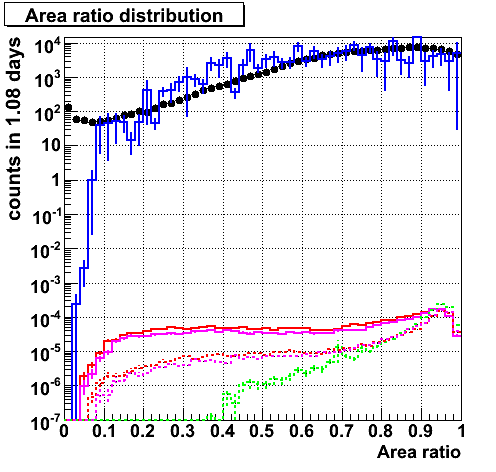
|
|
Gradient. Althouhg mismatch in bg, bg and 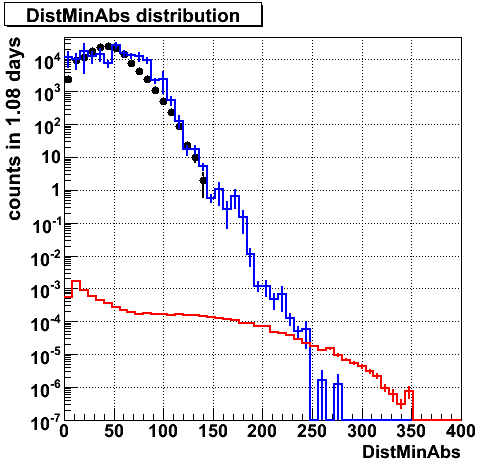
|
Gradient from each components. nue give high area ratio. 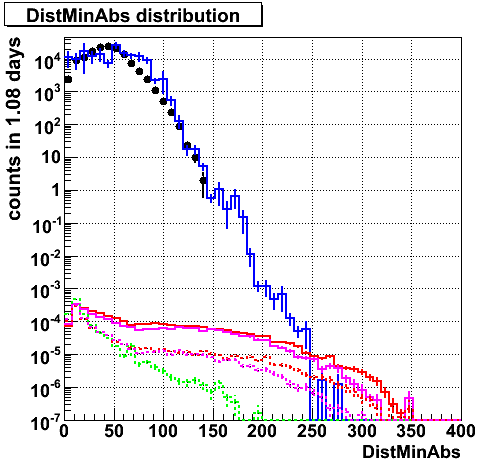
|
|
Gradient. Althouhg mismatch in bg, bg and 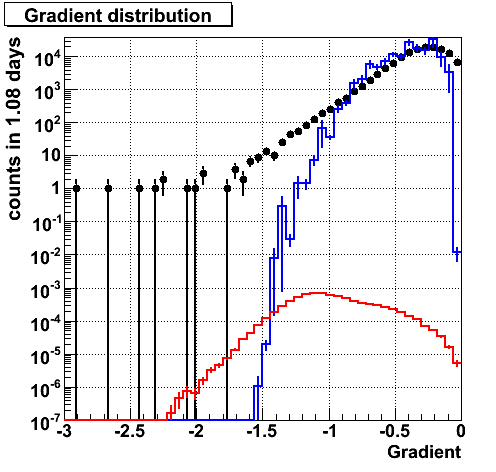
|
Gradient from each components. nue give high area ratio. 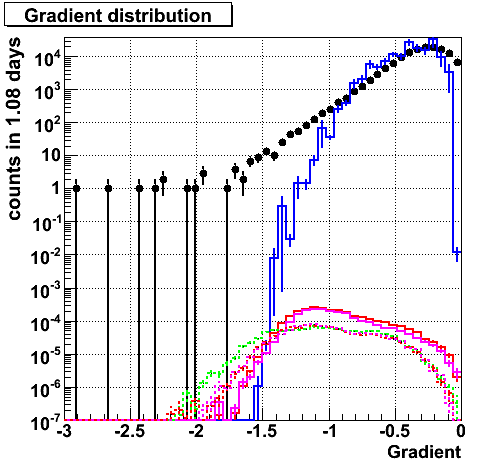
|
|
Energy 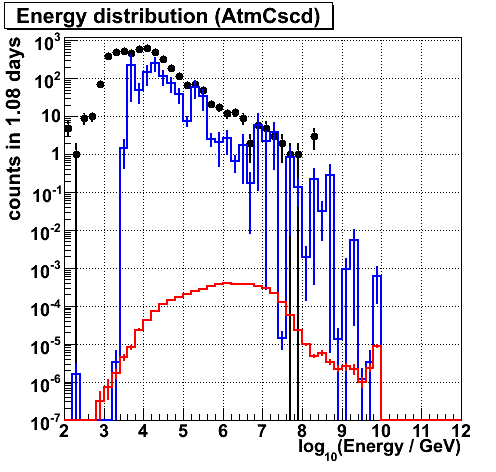
|
Energy 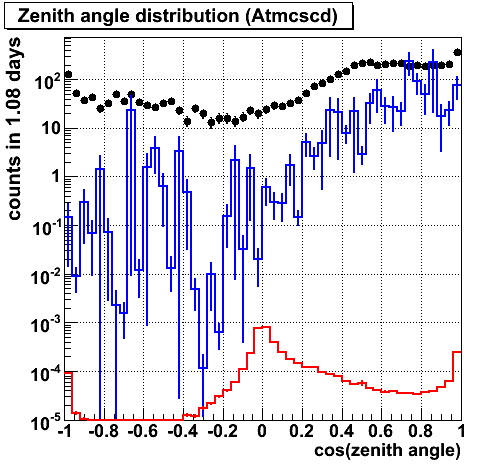
|
Nch 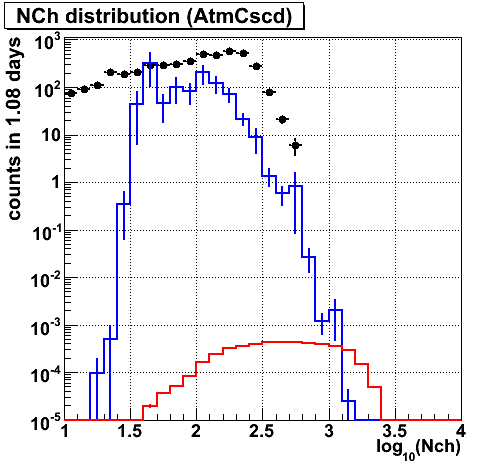
|
Mis-reconstruction may be problematic...
|
Zenith angle Vs NPE (data) 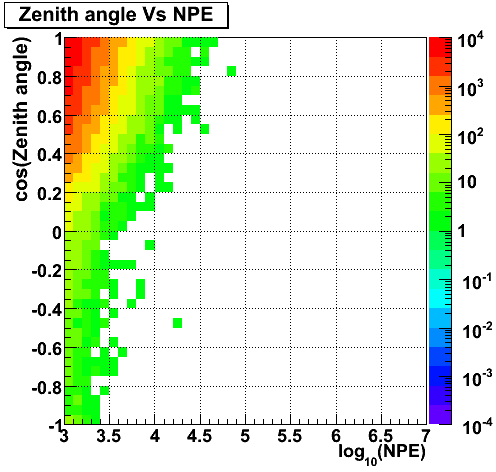
|
Zenith angle Vs NPE (CORSIKA) 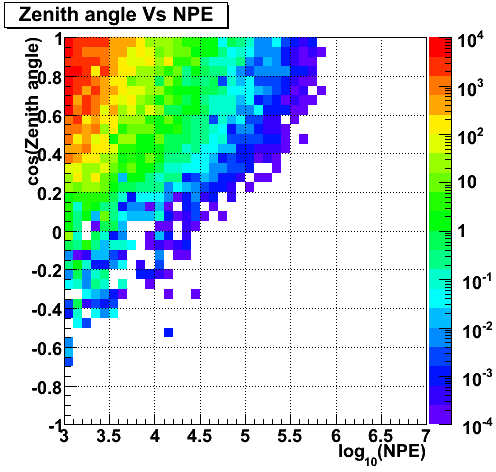
|
Zenith angle Vs NPE (GZK) 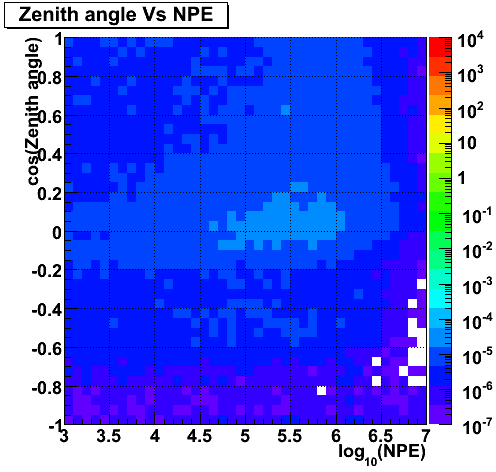
|
|
Zenith angle (mpe) Vs Energy (data) 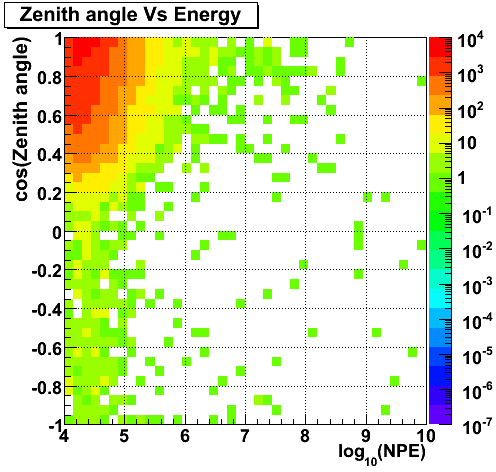
|
Zenith angle (mpe) Vs Energy (CORSIKA) 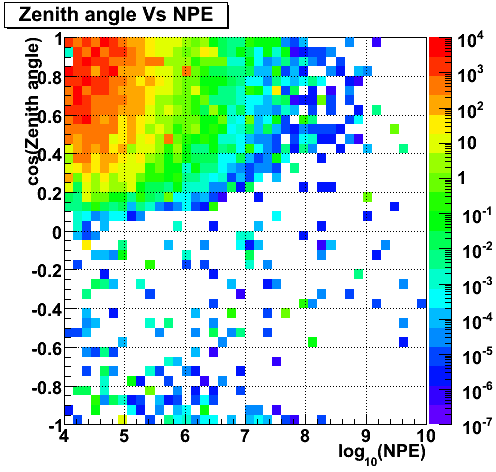
|
Zenith angle (mpe) Vs Energy (GZK) 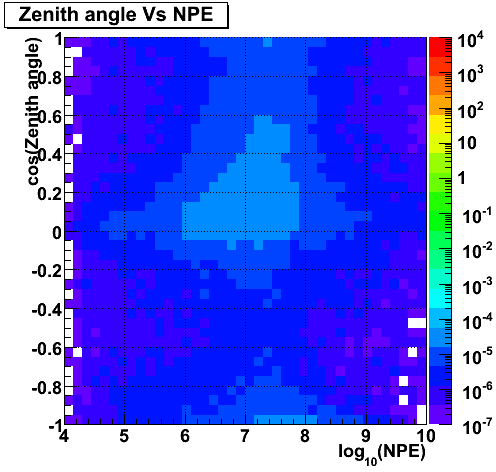
|